Statistics is a
mathematical science pertaining to the collection, analysis, interpretation or
explanation and presentation of data. It provides tools for predicting and
forecasting the economic, marketing, and other activities.
Meaning of Statistics: Statistics is concerned with scientific methods for
collecting, organizing, summarizing, presenting, and analyzing data as well as
deriving valid conclusions and making reasonable decisions on the basis of this
analysis. Statistics is concerned with the systematic collection of numerical
data and its interpretation. The word ‘statistic’ is used to refer to 1.
Numerical facts, such as the number of people living in particular area. 2. The
study of ways of collecting, analyzing and interpreting the facts.
TYPES OF STATISTICS:
1. Descriptive Statistics consists of methods for organizing, displaying, and
describing data by using tables, graphs, and summary measures.
2. Inferential Statistics consists of methods that use sample results to help make decisions or predictions about a population.
DESCRIPTIVE STATISTICS
Descriptive statistics is the term given to the analysis of
data that helps describe, show or summarize data in a meaningful way such that,
for example, patterns might emerge from the data. Descriptive statistics do
not, however, allow us to make conclusions beyond the data we have analyzed or
reach conclusions regarding any hypotheses we might have made. They are simply
a way to describe our data.
Descriptive statistics are very important because if we
simply presented our raw data it would be hard to visualize what the data was
showing, especially if there was a lot of it. Descriptive statistics therefore
enables us to present the data in a more meaningful way, which allows simpler
interpretation of the data. For example, if we had the results of 100
pieces of students' coursework, we may be interested in the overall performance
of those students. We would also be interested in the distribution or spread of
the marks. Descriptive statistics allow us to do this.
Typically, there are five general types of statistics that
are used to describe data:
 The
concept of skewness is mainly used to understand the distribution of the
data and steps taken to normalize the data for further building of machine learning models. In
case of negatively skewed data, Mean<Median<Mode. This indicates, more
data points are to the right of the curve here the data has very high values in
large numbers.
The
concept of skewness is mainly used to understand the distribution of the
data and steps taken to normalize the data for further building of machine learning models. In
case of negatively skewed data, Mean<Median<Mode. This indicates, more
data points are to the right of the curve here the data has very high values in
large numbers. 
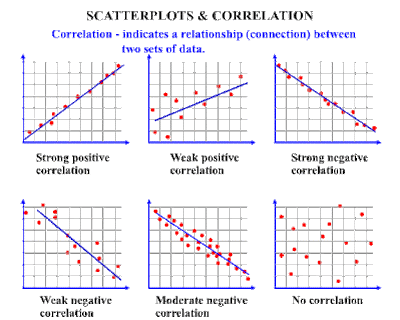 Example of correlation A correlation chart, also known as a scatter diagram, makes it
easier to visually see the correlation between two variables. Data in a
correlation chart is represented by a single point. In the chart above you can
see that correlation plots various points of single data. Let's think of
correlation as real-life scenarios. In addition to the price and demand
example, let's take a look at correlation from a marketing standpoint to see
the strength of a relationship between the two variables. For instance, it
could be in your company's best interest to see if there is a predictable
relationship between the sale of a product and factors like weather,
advertising, and consumer income.
Example of correlation A correlation chart, also known as a scatter diagram, makes it
easier to visually see the correlation between two variables. Data in a
correlation chart is represented by a single point. In the chart above you can
see that correlation plots various points of single data. Let's think of
correlation as real-life scenarios. In addition to the price and demand
example, let's take a look at correlation from a marketing standpoint to see
the strength of a relationship between the two variables. For instance, it
could be in your company's best interest to see if there is a predictable
relationship between the sale of a product and factors like weather,
advertising, and consumer income.
What is regression? On the other hand, regression is how one variable affects another,
or changes in a variable that trigger changes in another, essentially cause and
effect. It implies that the outcome is dependent on one or more variables. For instance, while correlation can be defined as the relationship between two variables, regression is how they affect each other. An example of this would be how an increase in rainfall would then cause various crops to grow, just like a drought would cause crops to wither or not grow at all. Regression analysis Regression analysis helps to determine the functional relationship between two variables (x and y) so that you’re able to estimate the unknown variable to make future projections on events and goals.
The main objective of regression analysis is to estimate the values of a random variable (z) based on the values of your known (or fixed) variables (x and y). Linear regression analysis is considered to be the best fitting line through the data points. Let’s use the example of tracking the value of a single share in the stock market over the years. X will be time in years and Y will be the value in dollars. We know that the value of a stock is changed by time passing, among other things. We can’t control those other things, but we can control when we sell the stock, so we control the time variable. But how dependent is the value of a stock on time passed? If we bought a stock for $1 and in one year its value went up to $100, does that mean every year the value will go up another $100? Does that mean in 25 years it will be valued at $2500? We don’t know. We figure it out by looking at how much the stock earned over several years. That’s fairly simple because we’re only measuring how much we change one thing or one variable. Then we put those measurements on a graph or plot. The dots could be all over the place or scattered. Could we draw a line through the dots that would show a trend? Let’s call that a trendline. Yes, we can certainly try. That line is a simple linear regression trendline through a scatter plot. For e.g. given below if the data of increase in share price year after year for 20 years. Time (Yrs) and stock value: 2000 - 1498, 2001 - 1160, 2002 - 1147, 2003 - 848.  The main advantage in using regression within your analysis is
that it provides you with a detailed look of your data (more detailed than
correlation alone) and includes an equation that can be used for predicting and
optimizing your data in the future. When the line is drawn using regression, we can see two pieces of
information: Regression
formula A → refers to the y-intercept, the value of y when x = 0 B
→ refers to the slope, or rise over run The prediction formula used to see how data could look in the
future is: Y = a + b(x)
The main advantage in using regression within your analysis is
that it provides you with a detailed look of your data (more detailed than
correlation alone) and includes an equation that can be used for predicting and
optimizing your data in the future. When the line is drawn using regression, we can see two pieces of
information: Regression
formula A → refers to the y-intercept, the value of y when x = 0 B
→ refers to the slope, or rise over run The prediction formula used to see how data could look in the
future is: Y = a + b(x)

 The main advantage in using regression within your analysis is
that it provides you with a detailed look of your data (more detailed than
correlation alone) and includes an equation that can be used for predicting and
optimizing your data in the future. When the line is drawn using regression, we can see two pieces of
information: Regression
formula A → refers to the y-intercept, the value of y when x = 0 B
→ refers to the slope, or rise over run The prediction formula used to see how data could look in the
future is: Y = a + b(x)
The main advantage in using regression within your analysis is
that it provides you with a detailed look of your data (more detailed than
correlation alone) and includes an equation that can be used for predicting and
optimizing your data in the future. When the line is drawn using regression, we can see two pieces of
information: Regression
formula A → refers to the y-intercept, the value of y when x = 0 B
→ refers to the slope, or rise over run The prediction formula used to see how data could look in the
future is: Y = a + b(x)
Differences between correlation and regression
There are some key differences between correlation and regression
that are important in understanding the two.
• Regression
establishes how x causes y to change, and the results will change
if x and y are swapped. With correlation, x and y are
variables that can be interchanged and get the same result.
• Correlation is a single statistic, or data point, whereas regression is the entire equation with all of the data points that are represented with a line. • Correlation shows the relationship between the two variables, while regression allows us to see how one affects the other.
• The data shown with regression establishes a cause and effect,
when one changes, so does the other, and not always in the same direction. With
correlation, the variables move together.
Similarities between correlation and regression
In addition to differences, there are some key similarities between correlation and regression that can help you to better understand your data. • Both work to quantify the direction and strength of the relationship between two numeric variables.
• Any time the correlation is negative, the regression slope (line
within the graph) will also be negative.
• Any time the correlation is positive, the regression slope (line within the graph) will be positive. So much more than just cause and effect
• Even though they’re studied together, it’s clear that there are obvious differences and similarities between correlation and regression. When you’re looking to build a model, an equation, or predict a key response, use regression. If you’re looking to quickly summarize the direction and strength of a relationship, correlation is your best bet.
T-Test
A t-test is a type of inferential statistic used to determine if
there is a significant difference between the means of two groups, which may be
related in certain features. It is mostly used when the data sets, like the
data set recorded as the outcome from flipping a coin 100 times, would follow a
normal distribution and may have unknown variances. A t-test is used as a
hypothesis testing tool, which allows testing of an assumption applicable to a
population.
For example:
•
• Compare if the people of one country are taller than people of
another one.
• • Compare if the brain of a person is more activated while watching happy movies than sad movies.
This comparison can be analyzed by conducting different
statistical analysis, such as t-test
Factor analysis:
Factor analysis is a way to condense the data in many variables
into a just a few variables. For this reason, it is also sometimes called
“dimension reduction.” You can reduce the “dimensions” of your data into one or
more “super-variables.” The most common technique is known as Principal
Component Analysis (PCA). Factor analysis is used to uncover the latent
structure of a set of variables. It reduces attribute space from a large
no. of variables to a smaller no. of factors and as such is a non dependent
procedure.
Example.
What
underlying attitudes lead people to respond to the questions on a political
survey as they do? Examining the correlations among the survey items reveals
that there is significant overlap among various subgroups of items--questions
about taxes tend to correlate with each other, questions about military issues
correlate with each other, and so on. With factor analysis, you can investigate
the number of underlying factors and, in many cases, identify what the factors
represent conceptually. Additionally, you can compute factor scores for each
respondent, which can then be used in subsequent analyses. For example, you
might build a logistic regression model to predict voting behavior based on
factor scores.
Discriminant analysis
Discriminant analysis is a versatile statistical method often
used by market researchers to classify observations into two or more groups or
categories. In other words, discriminant analysis is used to assign objects
to one group among a number of known groups. By performing discriminant
analysis, researchers are able to address classification problems in which two
or more groups, clusters, or populations are known up front, and one or more
new observations are placed into one of the known classifications based on
measured characteristics.
Discriminant analysis is also used to investigate how variables
contribute to group separation, and to what degree. For this reason, it’s often
leveraged to compliment the findings of cluster analysis.
Market researchers are continuously faced with situations in which
their goal is to obtain a better understanding of how groups (customers, age
cohorts, etc.) or items (brands, ideas, etc.), differ in terms of a set of
explanatory or independent variables.
These situations are where discriminant analysis serves as a powerful research and analysis tool.
Ref: Dr. Hanif Lakdawala's AMR Notes
No comments:
Post a Comment